This transcript has been edited for clarity.
Okay. You're in the emergency room, evaluating a patient who comes in with acute shortness of breath. It could be pneumonia, it could be a COPD exacerbation, it could be heart failure. You look at the x-ray to help make your diagnosis — let's say COPD — and then, before you start ordering the appropriate treatment, you see a pop-up in the electronic health record, a friendly AI assistant that says something like, "I'm pretty sure this is heart failure."
What do you do?
This scenario is closer than you think. In fact, scenarios like this are already happening in health systems around the country, sometimes in pilot programs, sometimes with more full-fledged integration. But the point remains: At some point, clinicians' diagnoses are going to be "aided" by AI.
What's the problem with AI predictions? Well, people often complain it's a "black box"; sure, it may tell me it thinks the diagnosis is heart failure, but I don't know why it thinks that. To make AI work well with clinicians, it needs to explain itself.
But a new study suggests that "explainability" of AI predictions doesn't make much difference in how doctors use it. In fact, it may make it worse.
We're talking about this study, "Measuring the Impact of AI in the Diagnosis of Hospitalized Patients: A Randomized Clinical Vignette Survey Study," appearing in JAMA, which takes a very clever approach to figuring out how AI helps — or hinders — a doctor's diagnostic ability.
In the study, 457 hospitalist physicians were presented with multiple clinical vignettes much like the one I opened with — a patient with acute shortness of breath. They had access to all the details, the medical history, and, importantly, the chest x-ray.
The doctors went through eight vignettes under a variety of scenarios. One was without any AI assistance, just to get a baseline diagnostic accuracy. On their own, the docs got about 73% of the cases correct.
Here's where it gets interesting. The team then had four AI conditions: First, a relatively accurate AI that did not give explanations for its thinking; second, that same AI but with explanations — in this case, highlights on the chest x-ray were added; third, a biased AI — it would always diagnose people with heart failure if their BMI was over 30, for example, without explanations; and fourth, that same biased AI but providing an explanation.
The hope, the expectation here was that forcing the biased AI to explain itself would help the clinicians realize that it was biased. Explainability becomes a safety feature of the AI model. Did it work?
Let me show you a couple of examples. Here we have the accurate AI, looking at an x-ray and determining, correctly in this case, that the patient has heart failure.
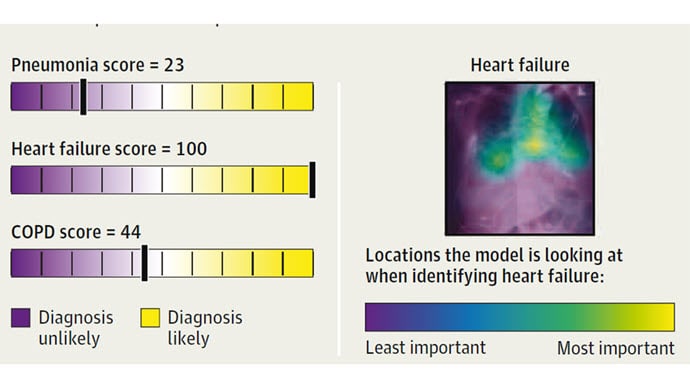
Importantly, the model is showing its work; it highlights the part of the chest x-ray that makes it think heart failure is going on, and we clinicians can say, "Sure, that makes sense. Pulmonary edema at the lung bases."
Here's the biased model predicting, quite strongly, that the patient has pneumonia. But the explanation is way off. It is highlighting part of the heart and chest wall — not the best places to diagnose pneumonia. Clinicians should be able to immediately recognize that the model is screwing up. But do they?

Clinicians' diagnostic accuracy improved modestly when the accurate AI gave advice, with a bit more improvement seen when the advice was accompanied by an explanation.

Their performance dropped substantially when the biased AI gave advice.

This is the first concerning finding of this study. It reminds us that AI can be helpful when it comes to diagnosis, but the effects of bad or biased AI might be much worse than the benefits of good AI.
Can we mitigate the risk of a biased AI algorithm by forcing it to include those explanations? Will clinicians disregard bad advice?
Not really. The diagnostic accuracy of clinicians was still harmed when the biased model explained itself. By and large, the presence of explanations did not act as a safety valve against a biased AI model.

This should be concerning to all of us. As AI models get put into practice, it's very reasonable for us all to demand that they are accurate. But the truth is, no model is perfect and there will always be errors. Adding "explainability" as a method to reduce the impact of those errors seems like a great idea, but the empiric data — from this study, at least — suggests it is far from a solution.
F. Perry Wilson, MD, MSCE, is an associate professor of medicine and public health and director of Yale's Clinical and Translational Research Accelerator. His science communication work can be found in the Huffington Post, on NPR, and here on Medscape. He tweets @fperrywilson and his new book, How Medicine Works and When It Doesn't, is available now.
Follow Medscape on Facebook, X (formerly known as Twitter), Instagram, and YouTube
Credits:
Image 1: JAMA
Image 2: JAMA
Image 3: F. Perry Wilson, MD, MSCE
Image 4: F. Perry Wilson, MD, MSCE
Image 5: F. Perry Wilson, MD, MSCE
Medscape © 2023 WebMD, LLC
Any views expressed above are the author's own and do not necessarily reflect the views of WebMD or Medscape.
Cite this: Beware of Biased AI - Medscape - Dec 19, 2023.









Comments